
皆さん、こんにちは。
南波真之(なんばさねゆき)と申します。
私はエンジニアではない文系の人間ですが、Pythonの可能性やデータ分析を使った仕事に興味があります。
前回はPythonの機械学習などを行う際によく使われるデータ解析のライブラリであるscikit-learnについて、基本の部分を取り上げてきました。Pythonを触る人であれば一度はやってみたい機械学習について実現できるライブラリとなっています。ご興味ある方はぜひご覧ください。
(参考: Pythonのscikit-learnで必要な機械学習を学ぶ)
さて今回は、scikit-learnの続きです。機械学習を行う際に必要となってくるのが「前処理」です。ここにフォーカスして学習を行いました。私が勉強している『Pythonによるあたらしいデータ分析の教科書(翔泳社)』の、P212.〜P.223の部分です。
前処理とは
データ分析には前処理がとても重要です。自分が持っているデータを前処理せずにデータ分析をしてしまうとエラーの発生や正確な結果が出ない、正確ではない結果のまま経営判断に使われてしまうという状況にもなりかねません。
そこで、前処理です。簡単にいうと、今あるデータを一度分析が正しくできるように整形する作業です。
前処理として、以下について勉強しました。
- 欠損値の処理
- 外れ値の処理
- カテゴリ変数のエンコーディング
- 特徴量の正規化
欠損値の処理
欠損値というのは、データの中で測定や通信等の不備によって生じる欠損した値(データ)のことを言います。データ分析においてはよく見るようで、欠損値があると分析結果がずれてきますので対応が必要です。
方法としては、欠損値の除去と補完があります。
欠損値の除去とは、欠損値が生じる行や列を削除してしまうことです。
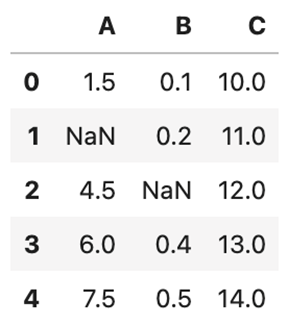
例えばDataFrameを使い意図的に欠損値を作成します。
| 必要なライブラリのインポート import numpy as np import pandas as pd サンプルのデータセット作成 df = pd.DataFrame( { ‘A’: [1.5, np.nan, 4.5, 6.0, 7.5], ‘B’: [0.1, 0.2, np.nan, 0.4, 0.5], ‘C’: [10.0, 11.0, 12.0, 13.0, 14.0] } ) df |
↓(出力結果)
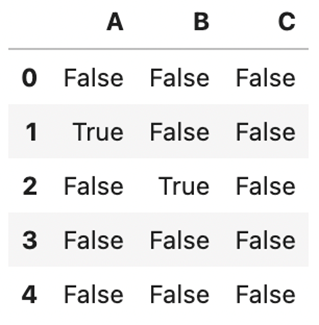
そして、isnullメソッドを使って欠損値を見つけます。欠損値はTrueが出力されます。
| df.isnull() |
↓(出力結果)
これらを削除するためにdropnaメソッドを利用して削除してしまうという形です。
続いて、欠損値の補完ですが、これは欠損値にある値を代入する処理となります。何を欠損値に補完するればいいのか、というと多くは特徴量の平均値や中央値、最頻値などを使うようです。
| from sklearn.impute import SimpleImputer 平均値 mean で欠損値を補完するインスタンス imp = SimpleImputer(strategy=’mean’) 欠損値を補完(前処理) imp.fit(df) imp.transform(df) |
↓(出力結果)

カテゴリ変数のエンコーディング
カテゴリ変数 = 限られた値において、どれに該当しているのかを示す変数
を使ったエンコーディングです。
カテゴリ変数を使う場合は、数値に変換してあげる必要があります。方法としては、
カテゴリ変数のエンコーディングと、One-hotエンコーディングが利用できます。
まず、カテゴリ変数のエンコーディングとは、カテゴリ変数を数値に変換することです。例えば、「a→0, b→1, c→2」のような形です。その場合はLabelEncorderクラスというのを作成して対応します。
まずはサンプルのDataFrameを作ります。
| import pandas as pd df = pd.DataFrame( { ‘A’: [1.5, 3.0, 4.5, 6.0, 7.5], ‘B’: [‘あ’, ‘い’, ‘う’, ‘え’, ‘お’], } ) df |
↓(出力結果)

そして、LabelEncorderクラスを使います。
| from sklearn.preprocessing import LabelEncoder # ラベルエンコーダのインスタンス生成 le = LabelEncoder() # ラベルのエンコーディング le.fit(df[‘B’]) le.transform(df[‘B’]) |
↓(出力結果)
array([0, 1, 2, 3, 4])
これでBに入っていた「あいうえお」がエンコーディングされて、「01234」になりました。
もう1つ、One-hotエンコーディングについてです。
これはテーブル形式のデータのカテゴリ変数の列について、取りうる値の文だけ列を増やして各業の該当する値の列だけに1が、それ以外の列には0が入力されるように変換していくものです。
外れ値の処理
外れ値は、データの中で明らかに値が異なるものです。この場合は正しい値に修正するか、行ごと修正してしまうか、そのまま使ってしまうかという選択を取ります。
外れ値をそのまま使うと多くの場合で結果が変わってしまうので処理は慎重になる必要があります。
外れ値の場合も欠損値の場合と同じようなアプローチで数値を補完するか削除するかを決め部分が必要です。
特徴量の正規化
特徴量の正規化は、尺度を合わせてブレを吸収させるものです。そのためには分散正規化や最小最大正規化を行う必要があります。統計っぽい話になってきました。
分散正規化は、特徴量の平均が0、標準偏差が1となるように特徴量を変換してしまう処理のことです。分散正規化をする際にはStandardScalerクラスを利用して実施します。
一方、最小最大正規化は特徴量の最小値が0、最大値が1となるように特徴量を正規化することです。
最小最大正規化をする際にはMinMaxScalerクラスを利用して実施します。
いずれもscikit-learnを使っていればすぐに利用できますのでとても便利です。
機械学習の理解とscikit-learnの理解の双方が必要
いかがでしたでしょうか。
今回はscikit-learnを使うための機械学習における前処理を学習してみました。まだまだ細かいところはたくさんありますので、これらは今後徐々に学習していく必要があるなと思いました。
インターネット・アカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。
よく、「プログラミングは独学でもなんとかなる」という情報もありますが、新しいことを学んでいく際の近道は「プロに教えてもらうこと」だと思います。
インターネット・アカデミーはキャリアサポートも充実しており、一人ひとりに専任のキャリアプロデューサーがサポートしてくれるため中途半端になることがありません。
ご興味ある方は各講座のページを覗いてみてください。無料カウンセリングもできます。
Pythonの基礎からDjangoフレームワークを使ったWebアプリケーションを作りたい方向けの「Python講座」
Pythonを活用したAIプログラミング、機械学習を実装したい方向けの「AIプログラミング講座」
