
皆さん、こんにちは。
南波真之(なんばさねゆき)と申します。
私はエンジニアではない文系の人間ですが、Pythonの可能性やデータ分析を使った仕事に興味があります。
前回は、分類手法の代表の1つでもあるサポートベクターマシン(SVM)について、サンプルデータから実際にSVMを作ってみることを取り上げてきました。
SVMとは機械学習のアルゴリズムで、2つのクラス(データのグループ)の分類を行うことを基本的な目的として利用します。分類のための境界線とそれに最も近い各クラスのデータ(サポートベクター)の間の距離が最も大きくなる(マージンの最大化)ような境界線(決定境界線)を引くということです。
ご興味ある方はぜひご覧ください。
(参考:データ分析学習コラム)
さて今回は、決定木とランダムフォレストについてです。私が勉強している『Pythonによるあたらしいデータ分析の教科書(翔泳社)』の、P234.〜P.242の部分です。決定木という方法を整理し、その上でランダムフォレストについて学習をしてみました。
決定木とは
決定木とは、Decision Treeとも呼ばれ樹形図の構造(ツリー構造)を使ってデータを分析する機械学習の方法です。
ツリー構造でデータを分けるルールを作っていくことで、データの分類をしていくアルゴリズムとなります。「要因」のデータと「結果」のデータが存在している教師あり学習の1つです。
よく情報の整理をするときに樹形図を描くことがありますが、まさにそのイメージになります。例えば、「顧客が男性かどうか」という一番上の情報(ルートノードと呼ばれる)があり、各ノードが繋がります。そして最深部のノード(ターミナルノードと呼ばれる)までの木構造です。ノード同士をつなげる線は「エッジ」と呼ばれます。
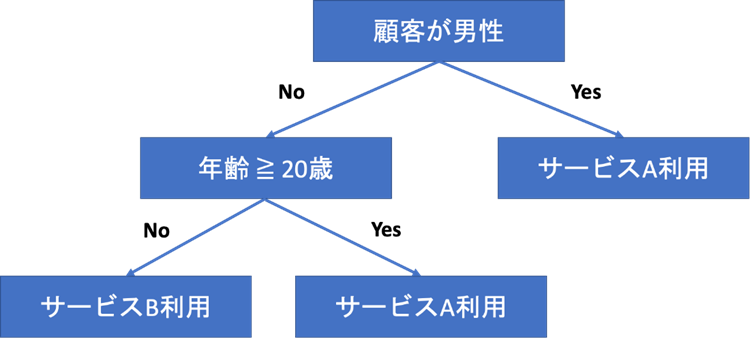
この決定木を使うメリットは、非常にわかりやすいからです。ツリー構造でそれぞれのノードの関係性が見ると把握できるため、プロセスの可視化ができます。
一方で、デメリットとしては決定木単体では、精度の高い予測ができないことがあります。これは、ランダムフォレストという仕組みで対応が可能になります。
この決定木をPythonを使って作る事ができますが、ポイントの1つはどの基準でデータをツリー構造に分割するかです。そのために、決定木の有名なアルゴリズムである、CARTを理解しましょう。
CARTは、特徴量の値に対して条件を「YesかNo」とすることによって予測を行う方法です。このCARTでGini係数というものを使って分類を行い分岐ができるようにしていきます。このGini係数は各クラスの偏り具合を表す指標で、不純度と呼ばれています。どれだけ間違いが各ノードに含まれているかを表すものです。
Gini係数は小さければ小さいほどきれいにクラスを分類できているということになり、不純度が少ない「0」に近づきます。そのため、Gini係数が小さくなるように分割をしていくのです。
試しに、irisのテストデータで決定木を出力してみました。
| from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier # データセット読み込み iris = load_iris() X, y = iris.data, iris.target # 学習データセット, テストデータセットに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123) # 決定木をインスタンス化, 決定木の深さを3にする tree = DecisionTreeClassifier(max_depth=3) # 学習させる tree.fit(X_train, y_train) |
↓(出力結果)
決定木の形で出力
| from sklearn.tree import plot_tree plot_tree(tree, feature_names=X_train, class_names=True) # データ抽出 plot_tree(tree,filled=True, rounded=True, class_names=[‘Setosa’, ‘Versicolor’, ‘Virginica’], feature_names=[‘Sepal Length’, ‘Sepan Width’, ‘Petal Length’, ‘Petal Width’]) |
↓(出力結果)
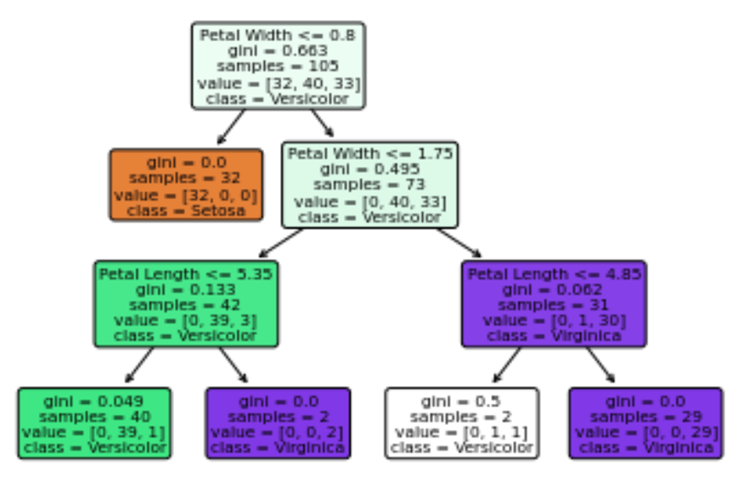
結果が少し見づらいのですが、一番上のノードにある 0.8 というのは閾値で0.8より大きいか小さいかでデータを分割しています。0.8以下の場合は、左下のオレンジ色のノードに移ります。0.8より大きい場合は右下のノードに移り、決定木を形成していきます。ちなみに、giniは不純度のことです。
この決定木を使った予測についても出してみます。
| tree.predict(X_test) |
↓(出力結果)
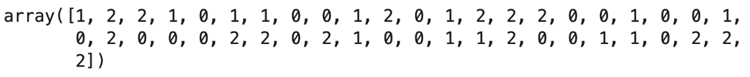
ランダムフォレストとは
ランダムフォレストとは、決定木をたくさん集めて多数決を取ることで、全体として分類ができているという分析方法のことです。
もう少し詳しく説明すると、データの特徴量をランダムに選択し決定木を構築するという処理を複数回繰り返すことで分類や回帰を行っていくものです。
ランダムに選ばれたサンプルと特徴量のデータをブートストラップデータと呼びます。
また、ランダムフォレストのように様々な機械学習モデルを組み合わせて精度の高いモデルを構築することをアンサンブル学習と呼びます。
ランダムフォレストの具体的な構築については、次回取り上げてみます。
決定木ランダムフォレストの理解
いかがでしたでしょうか。
今回は「決定木」と「ランダムフォレスト」という機械学習のアルゴリズムについて取り上げてきました。私を含む文系の人たちや今までデータ分析をやったことがない人たちからすると、理解するのがまず大変だったのではないでしょうか。
自分なりに学習した内容から、読者の皆さんが少しでも参考になったところがあれば嬉しいです。
インターネット・アカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。
よく、「プログラミングは独学でもなんとかなる」という情報もありますが、新しいことを学んでいく際の近道は「プロに教えてもらうこと」だと思います。
インターネット・アカデミーはキャリアサポートも充実しており、一人ひとりに専任のキャリアプロデューサーがサポートしてくれるため中途半端になることがありません。
ご興味ある方は各講座のページを覗いてみてください。無料カウンセリングもできます。
Pythonの基礎からDjangoフレームワークを使ったWebアプリケーションを作りたい方向けの「Python講座」
Pythonを活用したAIプログラミング、機械学習を実装したい方向けの「AIプログラミング講座」
