
皆さん、こんにちは。
南波真之(なんばさねゆき)と申します。
私はエンジニアではない文系の人間ですが、Pythonの可能性やデータ分析を使った仕事に興味があります。
前回はPythonでのデータ分析を容易にする機能のライブラリであるpandasについて取り上げてきました。Pandasを使う際の特有のデータ型DataFrameを使った多次元のデータの出力や取り出しをすることでデータの分析を行うことができる部分まで一緒に見ていきました。
ご興味ある方はぜひご覧ください。
さて、今回もpandas(パンダス)です。私が勉強しているPythonによるあたらしいデータ分析の教科書(翔泳社)の、P143.〜P.158の部分にある、pandasを使った外部データの読み書きやデータの編集について学習してみました。
pandasでのデータ読み書き
pandasとは、Pythonでのデータ分析を容易にするような機能のライブラリです。データ分析のツールとしてはとてもよく使われているものです。データ分析をする際には、手元にあるデータをまず整理するところから始まります。これを前処理と呼ぶこともありますがこのデータ整理で大きく効力を発揮します。pandasは、NumPyを基盤にして2つのデータ型があります。1次元データのSeries(シリーズ)と2次元データのDataFrame(データフレーム)です。
分析をするデータというのは、1から作るよりは外部のツールやファイルから出力されたデータという場合が多いかと思います。主流なところでいうと、CSVやExcelになるでしょう。例えば自分のPCにあるCSVファイルをpandasを使って読み込んでみて出力をし、そのデータをpandasで整理しNumPyなども使って分析していくというような流れが取れます。
pandasでのデータ読み込み
まずは、データの読み込みについてです。試しにCSVファイルを読み込ませてみます。
| import pandas as pd ## pandasで特定のCSVファイルの読み込み df = pd.read_csv(‘data/202204health-data.csv’, encoding=”utf-8″) df |
CSVの中のデータが読み込まれて出力されました。
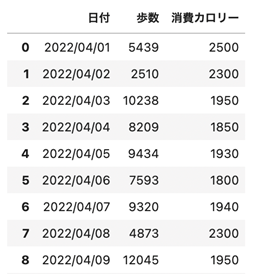
この読み込みで躓くところはCSVファイルの指定の部分になります。ファイルが見つからない事によるエラーはよく出ますので、読み込ませたいファイルをしっかりパス指定できているのかを確認しましょう。一番確実なのは絶対パス(Macであれば、/Users/ユーザー名/〜のなどのようになる)で指定してあげるといいです。
この手法はExcelでも可能で、Excelの場合はpd.read_csvの部分がpd.read_excelとなるだけです。
その他にもスクレイピングのような方法でWebサイトのHTMLを読み込んでデータを取り込むという方法もあります。
例えば、WikipediaのURLを指定してそこにある特定のテーブルを取得するなどです。
| ## WebページのHTMLからDataFrameに取り込み url = “https://ja.wikipedia.org/wiki/Python” tables = pd.read_html(url) ## インデックス番号4番(5番目)の表を取得 df = tables[4] df |
pandasでのデータ書き込み
次はデータの書き込みです。作成したDataFrameをCSVファイルで書き出すこともpandasを使うと可能です。
| ## CSVに書き出し df.to_csv(“’data/202204-new-data.csv’) ## Excelに書き出し df.to_excel(“’data/202204-new-data.xlsx’) |
これで該当の場所にファイルが出来上がることになります。
pandasを使って特定のWebページから読み込みを行ったDataFrameを編集して最終的にCSVファイルなどの形で書き出すという一連の流れができるようになります。
DataFrameをそのままファイルとして保存する
pandasには、今まで紹介してきたExcelやCSVの形式で書き出す他に、DataFrameそのままをファイル保存しておいて再利用させることも可能です。こちらのほうが手軽な気がします。
それは、pickleモジュールを使う方法です。
例えば、巨大サイズのCSVファイルを読み込み、データに手を加えていたとすると、CSVファイルの読み込みにも時間がかかってしまうことがあります。この場合に、1度CSVファイルを読み込んで、手を加えたところでファイルに保存しておくということを行います。これによって、
その後はそのファイルを読み込むだけで以前の作業結果を復元できるということです。
| ## Excelファイルを読み込み import pandas as pd df = pd.read_excel(“data/sampleデータベース.xlsx”) ## 出力 df |
出力は以下のようになります。
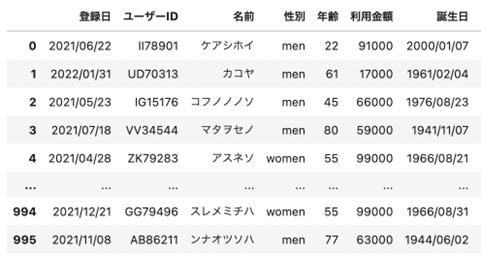
| ## pickleを使い、.pickleとして保存する df.to_pickle(“data/sampleデータベース.pickle”) ## 保存した.pickleのDataFrameを読み込み、dfに代入 df = pd.read_pickle(“data/sampleデータベース.pickle”) ## 出力 df |
出力は以下のようになります。
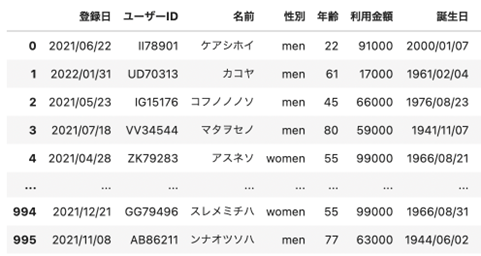
同じものが出力されました。
このように、pickleに保存をしておくことでDataFrameをそのままファイルとして保存して再利用できるようになります。
pandasでのデータの編集
pandasを使ったデータの編集もよく使われます。例えば、データの抽出、並べ替え、削除などです。大量のデータが単にDataFrameになっているというのはもったいないので、自分が見たいデータだけを取り出して手を加えていくようにしていきます。
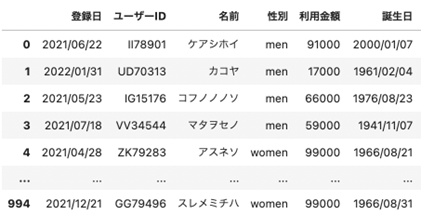
1つ目は、データの抽出です。特定の年齢帯の人だけを抽出したいという事はあると思います。
| ## 30歳以下の人のみ出力 df_selected = df[df[“年齢”] <= 30] df_selected |
出力はこのようになり、年齢が30歳以下の人だけがDataFrameとして出力されました。
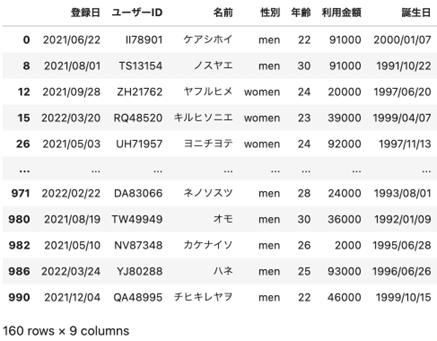
2つ目は、条件を増やしたデータの抽出です。年齢と利用金額の2つを基準に抽出した上でその関係性を見るということも分析では行うこともあります。
| ## 30歳以下の人かつ、利用金額が10万円以上の人 ## queryメソッドを使う df.query(‘年齢 <= 30 and 利用金額 >= 90000’) |
出力は、こうなります。問題なく指定した条件のデータのみが出力されています。
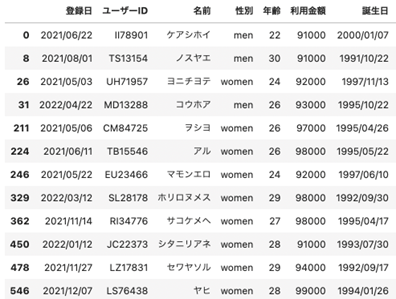
その他、データの並べ替えは以下のように行います。年齢が大きい順に並べていますが、小さい順に並べたい場合は ascending=True とすれば並ぶようになります。
| ## データの並べ替え df.sort_values(by=”年齢”, ascending=False).head() |
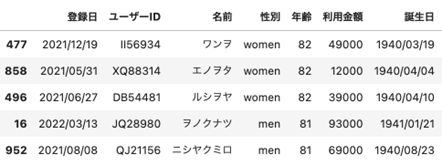
更に、表データを全て使う必要がない場合に、余分なカラムを削除するということも可能です。例では、「年齢」のカラムを削除しています。
| ## データ削除 df = df.drop(“年齢”, axis=1) |
出力結果を見ると「年齢」が消えてしまっていますね。
このように、DataFrameを様々自分の望ましい形にした上でデータ分析をしていくというのが基本的な流れとなってきます。
DataFrameを活用することで
いかがでしたでしょうか。
今回は、pandasのDataFrameのデータの読み込みから書き込み、そして編集というところを取り上げてきました。
Pythonにおけるデータ分析でpandasは使われることが多く、身につけておきたい知識の1つです。理解すべき項目も多いですが、細かい部分を理解しておくことで応用が効くようになると思いますので、頑張りましょう。
インターネットアカデミーは、Python講座が充実しています。Python認定スクールにもなっているため質の高い知識を得ることができ、基礎学習の先にあるそれぞれの目標を目指していくためには良い場所となります。
よく、「プログラミングは独学でもなんとかなる」という情報もありますが、新しいことを学んでいく際の近道は「プロに教えてもらうこと」だと思います。
インターネットアカデミーはキャリアサポートも充実しており、一人ひとりに専任のキャリアプロデューサーがサポートしてくれるため中途半端になることがありません。
ご興味ある方は各講座のページを覗いてみてください。無料カウンセリングもできます。
Pythonの基礎からDjangoフレームワークを使ったWebアプリケーションを作りたい方向けの「Python講座」
Pythonを活用したAIプログラミング、機械学習を実装したい方向けの「AIプログラミング講座」
